Appearance
Zookeeper
ZooKeeper 是一个高性能的分布式应用协调服务
介绍
Zookeeper 的常见服务有哪些?
- 命名服务
- 配置管理
- 分布式同步
- 组服务
Zookeeper 使用 c/s 模式,即客户端/服务端交互模式
CAP 理论
- Consistency 一致性 :数据在多副本之间保持一致
- Availability 可用性:每次请求都有正确相应,但不保证为最新数据
- Partition Tolerance 分区容错性:始终保证对外提供服务
对于分布式计算系统来说,不可能同时满足以上3点,而 Zookeeper 保证的是 CP,Eureka 保证的是 AP
BASE 理论
- Basically Available 基本可用:在分布式系统出现故障时,允许损失部分可用性
- Soft-state 软状态:允许分布式系统出现中间状态,且中间状态不影响系统的可用性
- Eventually Consistent 最终一致性:一段时间后达到一致性
BASE 理论其实是对于 CAP 理论中的 AP 的补充
应用
实现分布式锁
分布式锁是控制分布式系统之间同步访问共享资源的一种方式,分为两种:排他锁和共享锁
排他锁(写锁)
只允许加锁成功的事务进行读写操作,其他事务不能进行读写操作
- Zookeeper 客户端调用 create 方法创建锁的临时节点,谁创建成功谁获得锁,未获得锁的客户端注册一个 watcher 监听事件,以便重新获得锁
共享锁(读锁)
加锁成功的事务只能进行读操作,其他事务也只能添加共享锁
- Zookeeper 客户端调用 create 方法创建临时节点:/path/[hostname]-请求类型 W/R-序号
- 客户端调用 getChildren 接口来获取所有已创建的子节点列表,判断是否获得共享锁,对于读请求如果所有比自己小的子节点都是读请求或者没有比自己序号小的子节点,表明已经成功获取共享锁, 同时开始执行读操作。对于写请求,如果自己不是序号最小的子节点,那么就进入等待。如果没有获得共享锁,读请求向比自己序号小的最后一个写请求节点注册 watcher 监听,写请求向比自己序号小的最后一个节点注册 watcher 监听
推荐使用 curator 工具包封装的 API 来实现分布式锁
原理
Watcher 事件机制
- 客户端注册 watcher 事件
- 服务端处理 watcher 事件
- 服务端触发 watcher 事件
- 客户端回调 watcher 事件
数据一致性
Zookeeper 使用 ZAB 协议来实现分布式数据一致性,协议分两部分:
消息广播
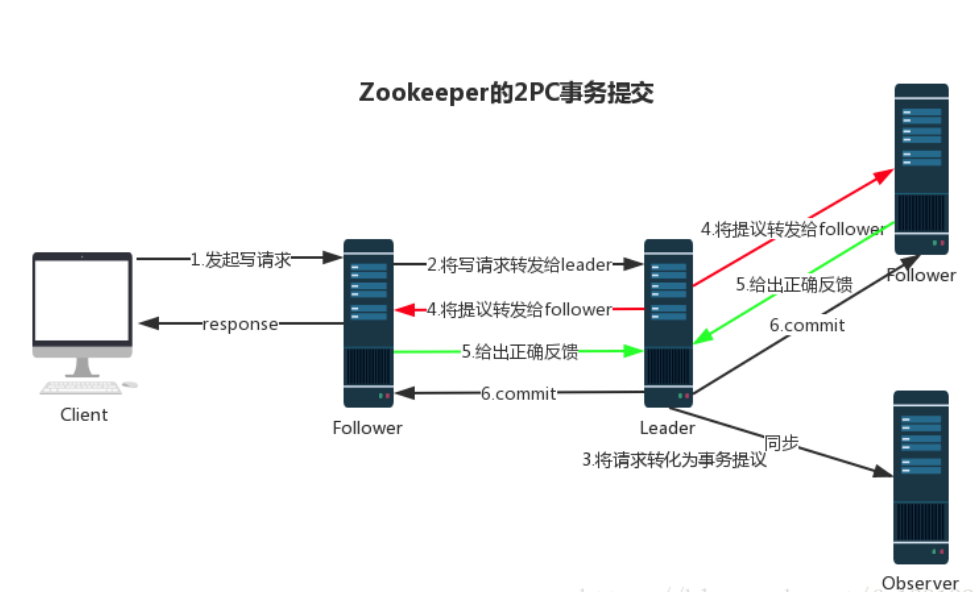
Zookeeper 使用单一的主进程 Leader 来接收和处理客户端所有事务请求,并采用 ZAB 协议的原子广播协议,将事务请求以 Proposal 提议广播到所有 Follower 节点, 当集群中有过半的 Follower 服务器进行正确的 ACK 反馈,那么Leader就会再次向所有的 Follower 服务器发送 Commit 消息,将此次提案进行提交。这个过程可以简称为 2PC 事务提交, 整个流程可以参考下图,注意 Observer 节点只负责同步 Leader 数据,不参与 2PC 数据同步过程。
崩溃恢复
在正常情况消息广播情况下能运行良好,但是一旦 Leader 服务器出现崩溃,或者由于网络原理导致 Leader 服务器失去了与过半 Follower 的通信,那么就会进入崩溃恢复模式,需要选举出一个新的 Leader 服务器。在这个过程中可能会出现两种数据不一致性的隐患,需要 ZAB 协议的特性进行避免。
1、Leader 服务器将消息 Commit 发出后,立即崩溃
2、Leader 服务器刚提出 Proposal 后,立即崩溃
ZAB 协议的恢复模式使用了以下策略:
1、选举 zxid 最大的节点作为新的 Leader
2、新 Leader 将事务日志中尚未提交的消息进行处理
Leader 选举
Leader 选举分两种:服务器启动时选举 Leader 和运行过程中 Leader 服务器宕机
服务器启动时选举 Leader
- 每台服务器发起一个投票,由于是初始情况,都会将自己作为 Leader 进行投票,投票涉及 服务器ID(myid)、事务ID(zxid)、逻辑时钟( epoch),发送给集群中的其他机器
- 收到投票后,检查投票有效性,检查是否本轮投票(比较 epoch),检查是否来自 LOOKING 状态服务器
- 处理投票,优先比较 epoch,其次检查 zxid,比较大的优先作为 Leader,如果 zxid 相同,那么就比较 myid,myid 较大的作为 Leader
- 统计投票,判断是否过半机器收到相同投票信息
- 改变服务器状态,如是 Follower,变更为 FOLLOWING,Leader 变更为 LEADING,OBSERVER 保持 OBSERVING 不变(不参与投票)
运行过程中 Leader 服务器宕机
- 变更状态,Leader 宕机后,非 OBSERVER 机器变更为 LOOKING
- 每个服务器发出一个投票,此时 zxid 可能不同
- 处理投票,与启动时相同
- 统计投票,与启动时相同
- 改变服务器状态,与启动时相同